

0
1
2
3
4
5
 ********
******** ********
********2021-07-01 -至今云上贵州大数据产业发展有限公司大数据工程师
1.帮助公司获得CMMI5级资质; 2.提出、实现富文本错别字纠错算法,并申请专利; 3.主导贵州省数据可信流通平台建设; 4.深度.参与贵州省数据流通交易平台建设; 5.深度参与公司数据开发管理平台建设; 6.深度参与公司内部信息化数据管理平台建设; 7.深度参与公司自研产品支部通研发; 8.深度参与公司主导的城运中心项目建设; 9.参与贵州省村级基础数据一张表建设; 10.参与贵政通项目运营、贵人码项目建设;
2015-07-01 -2018-08-01南京擎盾信息科技有限公司算法工程师
1.在文本自动摘要任务中,提出基于阅读理解的文本自动摘要方法。 2.在判断文本情感极性任务中,我提出 bert 和特征工程相结合的方法。 3.在普通网页的垃圾文本识别任务中,我提出了用无监督的方式实现垃圾文本识别。 4.在公司开发同案不同判预警系统这个项目中,我提议通过对裁判文书的各种情节进行打标签,然后利用随机森林这种bagging 模型来模拟多个法官的判案过程,实现案件的自动判决。
2018-09-01 - 2021-07-01南京大学计算数学硕士
硕士研究生·全日制普通硕士学位研究生(包括全日制学硕、全日制专硕)理学硕士 数学系 · 数学类-数学类-理学其他 南京大学优秀学术学位硕士学位论文
2011-09-01 - 2015-07-01同济大学统计学本科
大学本科·全日制普通本科理学学士 理学院数学系 · 数学类-数学类-理学前50%
以授权专利——《一种无监督的网络舆情垃圾长文本识别方法》,本发明涉及信息处理技术领域,具体为一种无监督的网络舆情垃圾长文本识别方,本发明的目的在于提供一种无监督的网络舆情垃圾长文本识别方法。
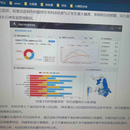
在公司开发同案不同判预警系统这个项目中,我提议通过对裁判文书的各种情节进行 打标签,然后利用随机森林这种 bagging 模型来模拟多个法官的判案过程,实现案件的自动判决,同时根 据随机森林的各棵树的决策路径实现相似案例的查找。目前该系统已经用于全公司。
通过一系列创新方法和技术,实现了富文本的智能纠错。从富文本解析方式,到特殊词汇的精确处理,再到多模型的纠错策略,以及纠错后文本的精确回填,本方法在每个步骤中都展现了独特的设计和创新思维。这些创新点共同确保了纠错过程的准确性、效率和可靠性,为富文本纠错处理提供了新的方法。







