


0
1
2
3
4
5

 ********
******** ********
********有很强的团队责任感:团队的利益和任务能保质保量按时完成
执行能力执行能力和团队适应力极强
具有很强的抗压能力and学习能力
拥有虚心工作,学习的态度
为人幽默,可以在百忙的团队工作情况下活跃团队气氛
2016-11-01 -至今单向工作室开发者
主要负责数据爬取 数据清洗 数据模型创建 训练数据模型 nlp 神经网络等项目的组合开发
2017-09-01 - 2021-07-31哈尔滨工程大学财务管理本科
2016-11-09 - 2020-07-31哈尔滨信息工程学院软件工程本科

获取网页源代码 正则提炼内容 数据清洗---格式化时间 正文爬取及数据深度清洗 打印清洗后的数据 数据导入数据库及数据去重 批量爬取处理多家公司

使用selenium抢票 只要功能实现自动化抢票 调用selenium也可以对反爬虫进行处理 滑动验证,无法解析js,数据瀑布流等问题都可以解决 selenium实现爬虫的自动化 获取数据或者执行模拟人操作的过程
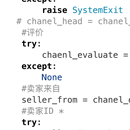
模拟器登录闲鱼 sdpy协议强制走http协议 解析json 在最后的一个阶段中,主要完成的是对刚刚发布信息的抓取。 2. 项目的主要难点在于对闲鱼 app 进行登录操作,因为软件有模拟器检测,所以在不断的破解和尝试各种 版本的安装包,以及模拟器的适配,从而完成对支付宝的下载,登录时即可直接登录闲鱼 app。 3. 项目的难点也在于如何筛选出哪些是刚刚发布标签的,由于*模拟器抓包获取的批量 json,一页中可 以存储十一条的商品信息,因此很大概率会在刚刚发布标签中掺杂一些数分钟之前的信息。我的选择是在选择到混 合刚刚发布以及其他信息的页面中直接中断掉。这样就获得了全部为需要的标签和数部分不需要的标签。将这混合 的标签放在新建 json 文件的最后一页。一定要按照顺序排序后放在最后一页。之后开始进行数据的清洗,清洗的 数据我将刚刚发布标签保留了下来,作为爬取中断的锲机。在清洗到获取 chanel_head,也就是刚刚发布标签。写 一个捕获异常的操作,将四个字作为定位符,一旦循环到第一个非刚刚发布标签,立刻将异常抛出,直接杀掉程序。 这也就是为什么我将混合的 json 放在最后一页。这样就筛选出哪些不是刚刚发布的标签,直接不解析,不存储。 三次异常的捕获抛出分别是程序中断返回空值以及在 json 文件头没有用户 id 时候就调到后文 ID 的位置





