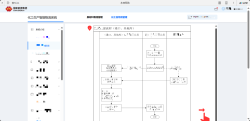
项目功能模块概述:
数据抓取模块: 实现从各种互联网源头如论坛、博客、新闻等抓取海量数据。
情报展示模块: 将抓取到的数据按照企业需求进行分析和展示,提供直观的情报,帮助企业制定竞争策略。
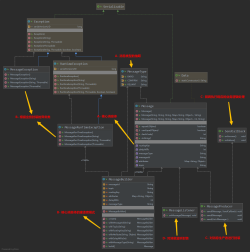
多源数据解析模块: 利用Java的htmlparser库进行html解析,提取关键信息,同时通过Python、Selenium、XPath等技术爬取Facebook、Weibo、小红薯、Google、Instagram、Twitter等平台数据。
Linux服务器支持: 构建强大的Linux服务器群,用于存储和处理海量数据。
用户实现的功能:
使用者可以通过系统从互联网各个渠道获取大量商业价值的情报数据,系统对数据进行解析和展示,帮助企业了解竞争环境,优化竞争策略。
我的贡献和技术栈:
负责模块: 我独立负责了从论坛和博客中抓取数据的模块,进行了grasper的优化,同时负责Linux服务器的部署,通过Shell脚本实现了持续部署能力。
使用技术栈: 项目核心技术包括Java的htmlparser库用于HTML解析,以及Python的Selenium、XPath解析等技术用于多源数据的爬取。