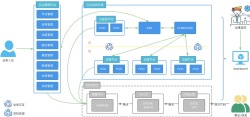
项目描述:
该项目主要是对公司内部数据进行汇总、存储、分析,挖掘其数据价值,提供统一的数据和服务,为前台业务提供强有力的数据支撑,其中主要的使用人群为数据分析/产品/运营人员,整个项目下又分为以提供web页面形式使用的报表、指标、舆情等子系统;还有以微服务形式提供服务支持的数据采集、数据通道等子系统;以及用于任务编排的调度系统。
责任描述:
1.负责项目技术架构图和数据流图的设计,制定项目工程的结构划分;
2.负责项目研发任务的管理、工作量评估、技术评估、协调沟通;
3.负责数据埋点项目的方案规化设计和研发工作的推进;
4.根据需求的增长和变更确保系统满足功能、性能以及可扩展性;
5.管理和分配项目中的功能任务,控制研发进度,协助团队成员按时完成研发需求;