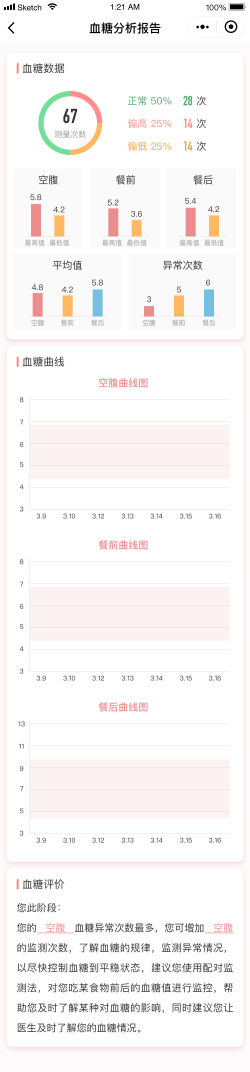
软件架构:SpringBoot + SpringCloud + SpringCloudAlibaba + nacos + Redis + RabbitMQ +Mysql 等
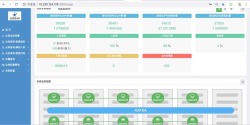
项目描述:该项目为商城精选购物平台。管理员可登陆后台管理系统对商品上架下架、管理订单,退款,积分提现 以及查看报表等功能。
用户在app端可以搜索选购,品牌购买,直播选购,分享省赚等功能。
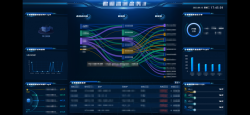
技术描述:后端整体使用 Springboot+SpringCloud +nacos 实现分布式集群部署,通过 nacos 充当服务配置中心和注册中心,
有网关认证服务,会员服务,商品中心,订单中心,交易中心,分销服务,营销服务, 分布式任务调度中心服务等核心模块;
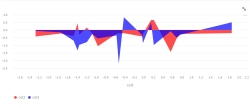
责任描述:负责会员服务、营销服务, 商品订单模块等具体模块业务设计和开发;对老系统进行系统升级,代码重构;服务支撑运营人员做数据分析,提取;