1、项目描述
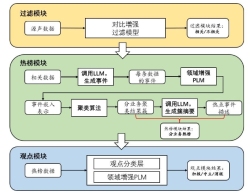
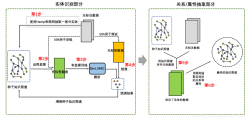
为了提高对互联网海量源声中舆情的分析能力,本项目构建了一个社媒数据的热点挖掘与观点提取系统。系统的主要目标为:
(1)对于海量互联网源声进行过滤,保留相关数据;
(2)基于过滤结果,对源声进行事件抽取与编码,聚类形成业务热榜;
(3)对于各业务热榜进行观点分类,得到热点事件的用户舆情。
2、主要工作
(1)根据任务特点,从零训练了中文GPT-4模型用于源声数据的事件生成,通过三个阶段分别训练模型的中文语言建模能力,通用摘要能力和针对任务的事件生成能力;
(2)分别训练了用于领域过滤,观点分类的模型,引入Prompt Learning,对比学习等技术提升模型性能;
(3)尝试使用中文大模型对热点事件模块进行优化,提升热榜准确率和可读性;
(4)完成服务的工程代码开发,各功能模块解耦,满足业务方的实际使用场景,部署服务到MLOPs平台。
3、项目成果
(1)截至目前,文本过滤模块和观点分类模块准确率均达到90%以上;
(2)舆论热榜模块聚类簇准确率达到87%,相较于原服务准确率提升20%;
(3)服务交付相关业务使用。
4、个人收获
(1)深度参与构建真实场景下的NLP应用系