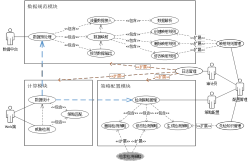
本项目是实现车辆经销商对自身客户的管理,让经销商能实现客户数据处理, 客户 360 画像, 客户分群, 客群筛选,基于客群的任务派发 等crm 核心功能。
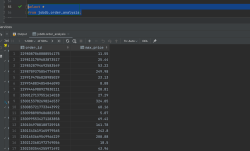
【1】客户数据处理模块 : 是处理多个来源的数据,统一入到一个 crm 库中, 进行数据的整合。 主要开发 2 个数据来源 :
[1] 基于经销商系统开发一个入口页面, 让经销商管理人员或者相关岗位专员进行数据的导入,包括车销数据, 信贷数据和部分工单数据
[2] 系统数据对接, 对接已有的主机厂系统,通过接口, oss, sftp 等方式对接主机厂的相关数据,包括工单数据, 零部件数据等
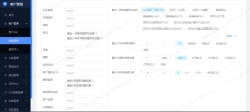
【2】客户360 , 将各个业务模块的数据整合到一起后, 在一个页面上全盘展示客户的全部信息, 包括车销,售后,信贷等业务线的标签画像,方便相关岗位专员在做业务跟进时,根据客户的全盘信息调整相应的销售策略与话术
【3】客户分群, 是 crm 的核心功能,是指客户基于后台已打好的客户标签来筛选出自己所需要的目标客群, 来实现营销,推广等业务落地, 例如 : 客户在9 月份计划举办一个'进店有礼'