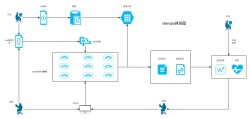
部署监控组件:
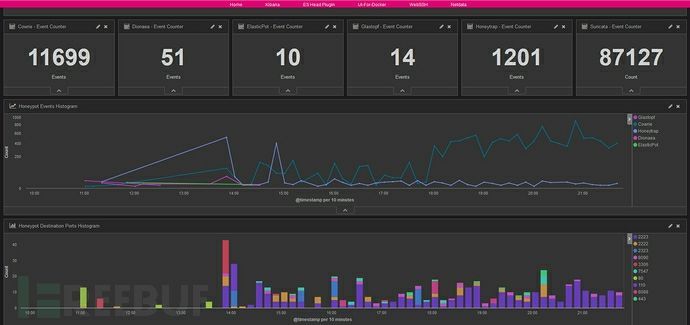
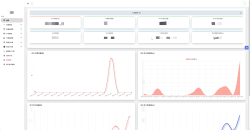
部署Prometheus和Grafana作为监控和可视化平台,用于收集和展示集群的各项指标。
部署Alertmanager作为告警管理器,用于接收和处理告警通知。
定义监控指标:
根据业务需求和集群特点,定义需要监控的指标,例如CPU利用率、内存使用量、网络流量等。
利用Prometheus的数据采集和查询功能,编写适当的配置文件和查询语句,以收集和存储这些指标的数据。
设计告警规则:
根据监控指标的阈值和规则,设计告警规则,例如当CPU利用率超过80%或者内存使用量超过阈值时触发告警。
通过Prometheus的告警规则配置文件,定义和管理这些告警规则。
配置告警通知:
使用Alertmanager的配置文件,定义告警通知的方式和目标,例如发送邮件、短信或者调用API接口。
根据告警级别和严重程度,设置相应的通知方式,以确保运维团队能够及时收到告警信息。
测试和优化:
在实施阶段进行测试和验证,确保监控和告警系统能够准确地检测和处理异常情况。
根据实际使用情况,持续优化和调整告警规则和通知方式,以提高系统的可靠性和准确性。