

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********Python、Shell、Linux、Kafka、ElastcSearch、DataWorks、Hologres 等数据建模计算,HQL/SQL 性能调优、Jieba、fastText、Sklearn,PyTorch,文本相似度计算,数值回归,TF-IDF关键词提取,基于凝固度和左右信息熵的新词发现,基于BiLSTM-CRF的命名实体识别
2021-03-08 -2022-08-31上海新榜信息技术股份有限公司算法工程师
技能:Python、Shell、Linux、Kafka、ElastcSearch、DataWorks、Hologres 等数据建模计算,HQL/SQL 性能调优、Jieba、fastText、Sklearn,PyTorch,文本相似度计算,数值回归,TF-IDF关键词提取,基于凝固度和左右信息熵的新词发现,基于BiLSTM-CRF的命名实体识别 职责描述: 1. 数据开发建模以及定制数据计算,项目数据质量监控,海量数据分区建模,平台实时数据聚合 ,周期任务调度,大批量离线数据聚合计算,异常监控,,主要使用 ElasticSearch、Hologres、DataWorks ,Python。 2. 新词、组合词发现,平台上线热词榜,热门词云。基于 jieba 进行大量文本原始数据词的初切分,插入前缀树,通过 ngrams 统计文本词频,计算各个 ngram 的凝固度,保留高于某个阈值的片段,通过凝固度+左右信息熵+词频的方式来进行新词发现,公式为:score = PMI + min (左熵, 右熵)。 3. 关键词提取,提供接口,为矩阵通业务项目赋能。品牌以及公司名称提取,前期确定需求共同
2017-09-01 - 2021-06-15四川大学软件工程本科
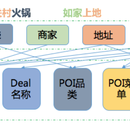
文本处理,内容及商品的品类、消费电商导向、货品需求词识别算法构建。货品需求词挖掘+商品分类体系的建设+识别规则制定,文本分类筛选需求品类,基于分词加规则的方式筛选出品牌,品类,导流平台等关键词,后期作为训练样本加入到实体识别中,生成命名实体识别(Bi-LSTM+CRF)模型,提升泛化能力。
平台上线热词榜,热门词云。基于 jieba 进行大量文本原始数据词的初切分,插入前缀树,通过 ngrams 统计文本词频,计算各个 ngram 的凝固度,保留高于某个阈值的片段,通过凝固度+左右信息熵+词频的方式来进行新词发现,公式为:score = PMI + min (左熵, 右熵)。

项目描述:“乾坤仪”是阿里巴巴营销洞察中心的一款业内新媒体监测产品,主要服务于天猫、淘宝、饿了么、阿里云、菜鸟、夸克等BU市场运营人员,用于在新媒体上评估活动效果、监测竞争趋势等,新榜主要为其提供数据支撑。 工作职责: 1. 原料准备,数据建模,数据清洗。跨多平台,使用python(numpy,pandas,matplotlib ,sklearn等)进行前期数据清洗,特征选择,发kakfa,DataWorks表分区存储,直播、商品、账号等多维度多层级映射关联。 2. 文本处理,内容及商品的品类、消费电商导向、货品需求词识别算法构建。货品需求词挖掘+商品分类体系的建设+识别规则制定,文本分类筛选需求品类,基于分词加规则的方式筛选出品牌,品类,导流平台等关键词,后期作为训练样本加入到实体识别中,生成命名实体识别(Bi-LSTM+CRF)模型,提升泛化能力。 3. 文本、数值等多维度特征提取挖掘,发现潜力、爆款商品和品类,为服务商、618和双十一赋能。基于阿里提供原型图中各子模块数据要求,进行跨表关联,多字段计算,完成数据挖掘,趋势洞察,配合提供定制化API,并协助乾坤仪的前端展示服务商,完成页面数据呈现。 4. 探索开源算法,扩展三方。短视频时代,样本更加倾向音视频,Google开源音频,阿里、华为、腾讯等第三方接口,基于识别效果、识别速率、存储方式等多维度,对音视频、图像进行识别和文本提取,反补文本较少的数据缺口。 5.周期同步,定制周期数据计算,监控报警,维护数据的稳定运行,保障数据质量和稳定输出,保证项目稳定交付。



