Python爬虫是一种用于从网页中提取数据的程序或脚本,以下是关于它的介绍:
定义与原理
- 定义:Python爬虫是利用Python语言编写的程序,能够模拟人类浏览器的行为,自动访问网页,并按照一定的规则提取和收集网页中的信息。
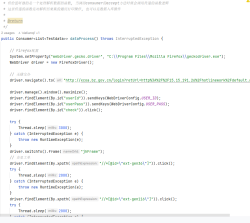
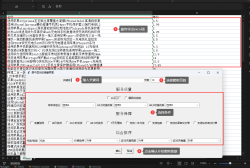
- 原理:首先,爬虫向目标网站发送HTTP请求,服务器接收到请求后返回对应的HTML页面。然后,爬虫使用解析库对HTML页面进行解析,提取出感兴趣的数据,如文本、图片链接、视频链接等。
常用库
- Requests:用于发送HTTP请求,获取网页内容。通过简单的函数调用,就可以轻松地向指定URL发送GET或POST请求,并获取服务器响应。
- BeautifulSoup:用于解析HTML和XML文档。它提供了简单的函数和方法,方便从解析后的文档中提取数据,可通过标签名、类名、属性等方式定位和提取信息。
- Scrapy:是一个功能强大的爬虫框架。它提供了更高级的功能,如自动处理请求、调度、持久化存储等,适合构建大型、复杂的爬虫应用。
应用场景
- 数据采集:用于收集各种网站上的数据,如新闻、商品信息、社交媒体内容等,为数据分析、机器学