首页
程序员
产品
招聘用人
云端工作
自由工作、远程工作
项目研发
需求梳理
规划落地您的想法
整包开发
一站式软件开发
云服务
UniSMS
合一短信 聚合API短信平台
技术
发布需求
开发者入驻
APP
登录
/
注册
全部
动态
开源项目
源文件源码
产品系统
Java
Python
C/C++
PHP
C#
TypeScript
Go
Swift
更多
网络爬虫
2019nCoV-Crawler 新型肺炎疫情数据爬虫
开源项目
爬冠状病毒新型肺炎疫情实时数据+数据持久化+邮件通知。 数据源来自“丁香园” :https://3g.dxy.cn/newh5/view/pneumonia_peopleapp?from=tim...
38
0
Java
网络爬虫
surfer 高并发爬虫下载组件
开源项目
surfer是一款Go语言编写的高并发爬虫下载器,拥有surf与phantom两种下载内核。 支持固定UserAgent自动保存cookie与随机大量UserAgent禁用cookie两种模式,...
60
0
网络爬虫
Scrapy-Python 网站爬虫框架库
开源项目
scrapy Scrapy:Python的爬虫框架 实例Demo 抓取:汽车之家、瓜子、链家 等数据信息 版本+环境库 Python2.7 + Scrapy1.12 初窥Scrapy Scrap...
64
0
Python
网络爬虫
CrawlerDemon 分布式爬虫
开源项目
CrawlerDemon 是垂直应用爬虫,基于akka+okHttp+spring+jsoup ,配置简单,上手容易,支持配置动态参数,动态代理,http自动重试。 特点 基于 akka 高性能...
65
0
Java
网络爬虫
vscrawler 适合抓取封堵的爬虫框架
开源项目
VSCrawler是一个适合用作抓取的爬虫框架,在更多场景倾向于功能扩展性而牺牲使用简便性。这让VSCrawler非常强大,让他可以灵活的应对目标网站的反爬虫策略。为了方便描述,文档中可能使用V...
57
0
Java
网络爬虫
DenseSpider 网络爬虫
开源项目
本项目 fork 项目go_spider,github:https://github.com/hu17889/go_spider ,因此项目架构的部分文档可以参考此项目。 同时项目架构、部分思路...
60
0
网络爬虫
WebCollector-Python 基于 Python 的开源网络爬虫框架
开源项目
WebCollector-Python WebCollector-Python 是一个无须配置、便于二次开发的 Python 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功...
40
0
Python
网络爬虫
Python-goose 用于文章提取的 Python 库
开源项目
Python-goose项目是用Python重写的Goose,Goose原来是用Java写的文章提取工具。Python-goose的目标是给定任意资讯文章或者任意文章类的网页,不仅提取出文章的主...
59
0
Python
网络爬虫
Egg Java Java 网络爬虫
开源项目
Egg 简介 Egg 它一个通用高效的爬虫,希望它能够替大家实现一些需求,更希望能为开源做出自己的贡献。目前,还在成长,在我的构想下,它还需要添加很多功能,我会继续完善。有任何疑问以及需求请以与...
101
0
Java
网络爬虫
Dodder 分布式 DHT 网络爬虫
开源项目
________ _________________ ___ __ \___________ /_____ /____________ __ / / / __ \ __...
55
0
Java
网络爬虫
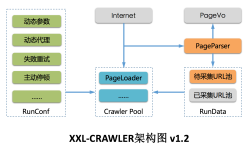
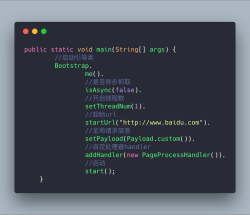
xxl-crawler 分布式爬虫框架
开源项目
分布式爬虫框架XXL-CRAWLER XXL-CRAWLER 是一个分布式爬虫框架。一行代码开发一个分布式爬虫,拥有"多线程、异步、IP动态代理、分布式、JS渲染"等特性; 特性 1、简洁:AP...
50
0
Java
网络爬虫
Zerg 基于docker的分布式爬虫服务
开源项目
zerg 基于docker的分布式爬虫服务 特性 多机多 IP,充分利用 IP 资源 服务自动发现和注册(基于 etcd 和 registrator) 负载均衡 服务端客户端通信基于 gRPC,...
131
0
网络爬虫
BeiJingSubwayFlows 北京地铁客流量统计工具
开源项目
北京地铁客流量统计(py爬虫+js统计图) 很好奇北京地铁每天的客流量变化,于是写了个爬虫。结果很有意思,每周7天的客流变化都很规律。 结果: https://www.ikaze.cn/sub_...
56
0
Python
网络爬虫
AntNest 简明飞快的异步爬虫框架
开源项目
AntNest 简明飞快的异步爬虫框架(python3.6+),只有600行左右的代码 功能 开箱即用的HTTP客户端 提供Item extractor, 可以明确地声明如何从response解...
48
0
Python
网络爬虫
神箭手云爬虫 快速开发爬虫系统的云框架
开源项目
神箭手云爬虫是一个帮助开发者快速开发爬虫系统的云框架。神箭手提供上手简单,灵活开放的爬虫云开发环境,让开发者只需要在线写几行js代码就可以实现一个爬虫。并且爬虫将自动运行在云服务器上,爬取速度更...
70
0
JavaScript
网络爬虫
VW-Crawler Java 爬虫框架
开源项目
VW-Crawler 背景 自己一直对爬虫比较感兴趣,大学的毕业论文也是一个爬虫项目(爬教务处信息,然后做了个Android版教务管理系统,还获得了优秀毕业设计的称号),自那以后遇到自己感兴趣的...
49
0
Java
网络爬虫
phpDhtSpider PHP 分布式 DHT 爬虫
开源项目
php实现的dht (BT种子)分布式爬虫 24小时采集 bt种子磁力链接信息 区别于传统爬虫 不会被封ip 采集效率 vultr 1核1G机器 每日大概8~10w条记录 github地址:ht...
55
0
PHP
网络爬虫
cetty 基于事件分发的爬虫框架
开源项目
一个轻量级的基于事件分发的爬虫框架。 功能介绍 基于完全自定义事件处理机制的爬虫框架。 模块化的设计,提供强大的可扩展性。 基于HttpClient支持同步和异步数据抓取。 支持多线程。 基于J...
44
0
Java
网络爬虫
Jedi-Crawler Node/PhantomJS爬虫
开源项目
Jedi-Crawler 是一款轻量级 Node/PhantomJS爬虫,可以动态的抓取网页内容。 安装: npm install jedi-crawler 示例代码: var jedi = r...
49
0
JavaScript
网络爬虫
SpiderGirls JAVA搜索引擎爬取框架
开源项目
SpiderGirls 是使用java编写的一个开源软件,使用它用户可以轻松地获得某个给定的关键字下的搜索引擎的结果,现在支持bing搜索和sogou搜索。 主页: https://github...
83
0
网络爬虫
当前共221个项目
1
2
3
4
5
6
7
8
9
10
...
登录
登录后即可上传、下载作品
搜索
分类
docker
Unity
flutter
在线帮助和支持系统
数据查询
智能硬件
可视化
Mysql
Atom 插件
iOS/iPhone/iPad开发包
×
寻找源码
源码描述
联系方式
提交
重点城市程序员兼职推荐
北京程序员兼职
上海程序员兼职
深圳程序员兼职
杭州程序员兼职
广州程序员兼职
成都程序员兼职
南京程序员兼职
武汉程序员兼职
西安程序员兼职
重庆程序员兼职
郑州程序员兼职
长沙程序员兼职
苏州程序员兼职
合肥程序员兼职
厦门程序员兼职
济南 程序员兼职
青岛程序员兼职
天津程序员兼职
大连程序员兼职
福州程序员兼职
石家庄程序员兼职
沈阳程序员兼职
太原程序员兼职
无锡程序员兼职
南昌程序员兼职
哈尔滨程序员兼职
南宁程序员兼职
珠海程序员兼职
宁波程序员兼职
昆明程序员兼职
东莞程序员兼职
贵阳程序员兼职
美国程序员兼职
长春程序员兼职
温州程序员兼职
佛山程序员兼职
常州程序员兼职
呼和浩特程序员兼职
兰州程序员兼职
乌鲁木齐程序员兼职
中山程序员兼职
海口程序员兼职
洛阳程序员兼职
更多
重点岗位程序员兼职推荐
C++兼职
Rust兼职
小程序兼职
cocos2d-x兼职
Unity3D兼职
DBA兼职
运维兼职
测试兼职
移动其他兼职
Go兼职
UE设计师兼职
全栈兼职
技术创始人兼职
CTO兼职
项目经理兼职
产品经理兼职
原画师兼职
UI设计师兼职
前端兼职
iOS兼职
Android兼职
Node.js兼职
Ruby兼职
架构师兼职
Python兼职
C#兼职
C兼职
PHP兼职
Java兼职
鸿蒙兼职
区块链兼职
人工智能兼职
硬件开发兼职
更多
您好 👋
我们能提供什么帮助?
向我们发送消息
常见问题、使用帮助、人工咨询等
智能搜索
手机访问
使用微信扫一扫