

0
1
2
3
4
5
0
1
2
3
4
5

 ********
******** ********
********孙云
使用annaconda3、pytorch、torch、cudnn、cudn、python
shell、sql、java、Linux、html,css
会:人工智能算法。
生物实验。
测试框架TestNG,JUnit5使用,抓取页面元素,运行脚本。
游戏白盒测试。
zip压缩包的明文攻击。
2022-01-09 -2022-08-18上海凝恩生物生物信息
使用Linux系统算法。 使用数据库 修改Linux文件 控制甘油变量,制作配液表。 数据记录后用科学统计软件观察甘油用量对发酵大肠杆菌的影响 通过实验分析找到对甘油的最佳用量 单因素实验(多因素实验:交叉分组)研究甘油用量对菌体培养量的影响。控制卡那霉素量研究卡拉霉素对发酵的影响
2019-07-14 - 2022-07-14江西医学高等专科学校生物技术专科
大肠杆菌发酵 清场 洗罐 灭菌:1、清洁发酵间 2、包装软管和勺子 发酵:连续发酵、半连续发酵、分批发酵 1、种子一级培养 2、二级种子培养 3、标定电极 4、配液:分批培养基、补料培养基、盐溶液 组罐 1、给发酵罐通空气 2、蠕动泵 3、接种
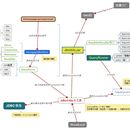
java安装文件结构 SDK:软件开发包 jdk代码(封装好的功能),java开发包,是SDK的子集 jre运行环境(对应各种软件程序,保证运行) 源文件的声明规则: 1、一个源文件只能有一个public类 2、一个源文件可以有多个public类 环境变量: windows linux 数据类型 1、基本数据类型 2、引用数据类型 方法重载:在一个类中,通过不同的参数列表来区分同名的方法 访问控制符 static关键字 final关键字 单例模式:饿汉式、懒汉式 集合框架: Collection接口 ->List接口,线性表。 -->ArrayList类,动态数组,寻址效率更高。 -->LinkedList类,链表,插入删除更新效率更高。 ->Queue接口,队列。由LinkedList实现。先进先出。 -->Deque接口,双端队列。由LinkedList实现。可以从两端进出,如果控制从一端进出,可以实现栈(stack)的数据结构。 Set接口:不重复数据集合 -->HashSet类 -->TreeSet类 Iterator接口: 用于遍历集合元素,主要提供了3个方法,hasNext(),next(),remove() Collections类: 提供一些方法用于操作集合对象 Map接口,查找表,值为键值对的形式,key-value,key不存在重复的,可以通过key访问value值 ->HashMap类 ->TreeMap类 泛型:在定义接口或者类时,可以定义其中的方法的参数或者返回值为一个泛型(Object),在实际实现或者调用时可以指定一个确定的类类型。这样使方法更灵活。集合中的方法基本都为泛型方法。泛型检查在编译期进行,在运行期不执行。可以通过反射调用绕开泛型检查。 异常处理: throw语句:在方法中抛出指定异常对象 throws关键字:声明在方法外,将方法中发生的异常做抛出处理,不在方法中进行处理,调用该方法会得到抛出的异常,可以选择处理,或者继续抛出。通常只抛检测异常。 异常分类: 1.非检测异常,在编译代码时,该类型异常不需要进行处理,属于运行期异常。RuntimeException()。 2.检测异常,在编译代码时,该类型异常必须得到处理或抛出,否则无法通过编译,属于编译期异常。 3.自定义异常 反射类:通过反射返回Class对象,来访问类构造器、类属性、类方法。 1.通过类的对象,反射Class对象——Class 对象 = 类对象.getClass() 2.通过类来反射Class对象——Class 对象 =类.class 3.通过Class.forName(String 类路径),反射Class对象——Class 对象 = Class.forName(String 类路径) IO类 java.io.File java.io.FileWriter java.io.BufferedWriter java.io.FileReader java.io.BufferedReader 枚举enum 多线程: 1.通过继承Thread类,改写类中的void run()方法,通过void start()来启动线程。 2.通过实现Runnable接口,实现接口中的void run()方法,通过接口对象构建Thread类对象。 3.通过实现Callable接口,实现接口中的V call()方法,通过接口对象创建FutureTask包装器对象,通过包装器对象构建Thread类对象。 4.通过实现Callable接口,实现接口中的V call()方法,ExecutorService创建线程池对象,通过线程池对象执行实现的接口方法,得到返回值返回到Future对象中。 守护线程:会在其他线程结束后结束 线程锁:synchronized 修饰方法,来锁定整个方法 修饰代码块,来锁定部分语句 锁定对象:1.锁定类的类的对象,this 2.锁定类,类名.class 3.锁定具体对象,对象名

函数 内置函数: 数据类型转换函数 len() 函数 写函数:1、告诉计算机,要定义一个函数 2、函数的名字是什么 3、这个函数需要输入什么参数 4、参数的处理过程是什么样的 5、把什么样的处理结果还给输入者 参数:形参 、默认参数、实参、位置参数、关键字参数 变量:全局作用域、局部作用域(global 关键字) 类与面向对象编程 面向过程:C语言 面向对象:对象=属性(特征、变量)+方法(行为、定义在类的函数) 类的实例化:__init__() 方法initialize(初始化) 继承 与 多态:子类重写父类方法、方法的多态性 条件分支——布尔表达式:三元表达式、二元表达式 多路分支:多选一问题,让计算机先判断最难满足的条件 多个条件语句:多次选择,选择结果互不影响 嵌套条件:前一个选择的结果会影响后面的选择 条件判断——布尔运算符: 取反运算符:! 且运算符:&& 或运算符:|| 三元运算符:?: 比较运算符:==(等于);!=(不等于);>(大于);=(大于等于);

有监督算法: ML机器学习:极大似然估计、中间极限定理、多元线性回归、泰勒展开公式 深度学习——逻辑回归LR:Softmax回归、交叉熵损失函数、sigmoid函数二分类 神经网络——网络拓扑: DNN深度 CNN卷积 RNN循环 对抗神经网络GAN ——激活函数: 非线性变换sigmoid Tanh 双曲正切函数hyperbolic tangent function Relu线性整流函数(Linear rectification function),又称修正线性单元 训练神经网络 向前阶段→正向传播(存储每一层的输出x/a,每一层的Z) 向后阶段→反向传播 1、求梯度,调参数 2、算出每一个参数对loss的贡献进行比较 3、求出残差 求前一层的梯度会用到后一层的梯度 通过for循环计算完正向传播和反向传播再进行“更新” 决策树DT:(二叉树,多叉树——信息增益率) 回归:MSE作为损失函数 分类:交叉熵cross-entropy作为损失函数 防止过拟合——前剪枝: gini系数 树的最大深度(层数) random_state随机种子 class_weight类别权重 后剪枝: REP—错误率降低剪枝 PEP—悲观剪枝(C4.5) CCP——代价复杂度剪枝(CART) 集成学习: Stacking:堆叠(多个阶段):GBDT+LR Bagging(随机森林):并行,有放回的抽样(按行) base model基模型→聚合模型 Aggregation Model Boosting:串行(需要第一个模型) 图模型:隐含马尔可夫模型 无监督算法: 聚类(K-均值算法) W模型参数 防止过拟合调整w:正则化 惩罚项——L1,L2 梯度下降法:求参数(权重,θ/w值) 设置“超参数” 1、初始化参数(initialization) 2、求gradient(斜率/梯度值):梯度是loss/cost对变量θ(x轴)求导 3、调整θ:调整幅度——设置η学习率 4、终止条件:设置threshold阈值,计算收益 损失函数loss 矩阵——转置、矩阵乘法、逐点加法、逐点乘法 数据预处理: PCA降维 归一化: 最大值最小值归一化 标准归一化(方差归一化) feature extraction特征抽取 使用工具包:Numpy、sklearn 环境:CUDA、annaconda3、pytorch、torch、cudnn





