项目名称:二手房数据抓取与存储系统
项目简介:
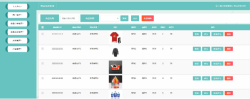
本项目旨在实现一个自动化的数据抓取工具,用于抓取二手房出售信息,并将提取的数据存储到MongoDB数据库中。该工具采用Python编程语言,结合了requests库进行网络请求、lxml库进行HTML解析以及concurrent.futures模块进行多线程处理,实现了高效的数据采集和存储功能。
系统架构:
系统主要分为以下几个部分:
1. 数据抓取模块:使用requests库向目标URL发送HTTP请求,获取网页内容;利用lxml库解析HTML源码,提取所需数据。
2. 数据解析模块:对抓取到的数据进行清洗和格式化,提取出房源标题、小区名称、房屋详情、价格等关键信息。
3. 数据存储模块:将解析后的数据通过MongoDB连接器批量插入到数据库中,同时提供了事务回滚机制以保证数据的一致性。
4. 多线程执行模块:利用ThreadPoolExecutor管理多个线程并发执行数据抓取任务,提高整体效率。
核心功能:
1. 自动化数据抓取:通过配置好目标URL,工具能够自动访问链家网的二手房页面,并获取相应的房源信息。
2. 数据解析与存