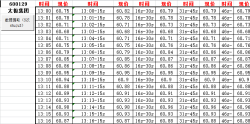
该项目旨在从特定网站上爬取数据,并将其保存到本地或者进行进一步的处理分析
Requests:用于发送HTTP请求获取网页内容。
Beautiful Soup:用于解析HTML网页内容,提取所需数据。
Scrapy(可选):一个强大的爬虫框架,提供了更多的功能和灵活性。
数据存储:可以使用各种方式,比如保存为文本文件、CSV文件、JSON文件,或者存储到数据库中(如SQLite、MySQL等)。
发送HTTP请求获取网页内容。
解析网页内容,提取所需数据(如标题、内容、链接等)。
保存提取的数据到本地文件或者数据库。
处理异常情况,如网络连接错误、页面解析错误等。
支持多线程/异步操作,提高爬取效率。
可配置化:允许用户指定爬取的起始URL、要爬取的数据类型等。